0. 빅데이터 강의를 수강하게 된 이유
평소 생활하면서 유튜브나 SNS 등 여러가지 생산형 플랫폼들에서 엄청난 양의 데이터들이 생성되고 이를 어떻게 관리할 것인지에 대한 의문이 생겼었다. 사실 데이터가 아무리 많다하더라도 DB 구조를 잘 설계하면 되지 않나 생각했었고, 많은 데이터를 효율적으로 찾기 위해 자료구조와 알고리즘이 있는게 아니었나라는 생각까지 있었다. 하지만 빅데이터라는 수업이 있는 만큼 또 뭔가 다른 방법이 있지 않을까 하는 작은 호기심에 듣기도 했고, JAVA를 사용한 JPA를 들을 수 있다니.. 안 들을 수가 없었다.
1. 빅데이터의 중요성
- "더 많은 데이터가 더 좋은 알고리즘보다 낫다"
- 비즈니스 성과 개선
- 예측 정보 활용
2. 3V
Volume : 테라바이트, 페타바이트
Velocity : 데이터 생성과 저장, 분석 과정의 속도의 중요성
Variety : 데이터의 다양성
- 정형 데이터 (Structured Data)
구조화 되어있는 데이터 : RDB, 스프레드시트, CSV 등
- 반정형 데이터 (Semi-Structured Data)
형태가 있으나 연산이 불가능한 데이터 : XML, HTML, JSON, 웹로그 형태 등
- 비정형 데이터 (Unstructured Data)
형태도 없고 연산도 불가능한 데이터 : 이미지, 음성, 텍스트 등
3. RDBMS
RDB(Relational Database) : 행과 열로 이루어진 테이블 형태의 데이터 구조와 연결을 정의한 모델
Schema : DB 구조와 Constraints에 관해 정반적인 명세
- 엄격한 스키마 구조에 따라 설계 단계에서 고려되지 않은 데이터 저장을 허용하지 않음
=> 개발속도 저하, 능동적인 데이터 저장의 어려움, 반/비정형 데이터 저장의 어려움
Relation : 데이터를 여러 테이블, Entity로 구분하여 저장하고 관계 정의
=> 복잡하고 상황에 따라 느린 조인이 필요하다.
4. NoSQL
Non-Relational Operational Database SQL, Not Only SQL
대표적으로 JSON형태의 파일을 다루는 MongoDB
다른 NoSQL 솔루션 : Redis, Hbase
출연 배경 : 비정형 데이터를 보다 쉽게 저장하는 분산처리 시스템의 필요
특징
- 확장성
- 유연성
- 고성능
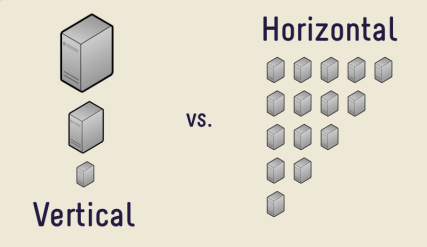
5. SQL VS NoSQL : 확장성
- 수직적 확장(scale-up) : SQL 방식
- 수평적 확장(scale-out) : NoSQL에 적합