0. 인터랙티브 인공지능 강의를 듣게된 이유
내가 알기론 작년 과목 명이 딥러닝이었는데 인터랙티브 인공지능으로 변경되었다.
과목 명이 변경되었지만 강의자료는 모두 딥러닝으로 수업이 진행되었다.
지난 학기에 배웠던 인공지능 수업의 연장선으로 개인적인 느낌으로 컴퓨터 공학이라는 현대 학문에서 정점에 존재하는 세부 전공이 아닐까 생각되었고, 이를 어떻게 활용을 해야할까라는 의문이 아직 해결되지 않았다.
딥러닝 강의에서 이 의문이 해결될까?라는 또 다른 의문에서 강의를 듣게 되었다.
1. 인공지능과 머신러닝 그리고 딥러닝

딥러닝은 기존 인공신경망의 진화된 기술이다.
이름에서 알 수 있듯 인공신경망은 생물학적 뉴런 신경망의 구조를 본따 소프트웨어로 구현한 것이다.
위 그림처럼 머신러닝은 어떠한 입력에 대해 특징 추출을 프로그래머 혹은 분석가가 진행하여 소프트웨어가 분류작업을 하고 결과를 도출하는 한편,
딥러닝은 어떠한 입력에 대해 특징 추출까지 소프트웨어가 진행하여 결과를 도출한다.
2. 인공신경망 (Artificial Neural Network, ANN)
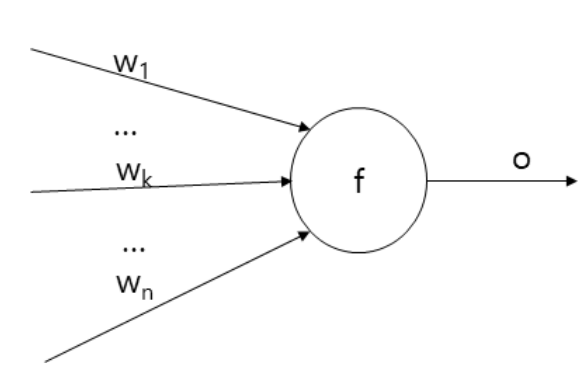
인공신경망은 n개의 입력을 받고, 각 입력에 대해 가중치를 곱한 후, 이 합에 활성화 함수(activation function)을 적용하여 값을 출력한다.
그리고 이 출력한 값이 다시 다른 뉴런의 입력으로 전달하도록 한다.
3. 다층 신경망 (Multi-Layer Perceptron, MLP)
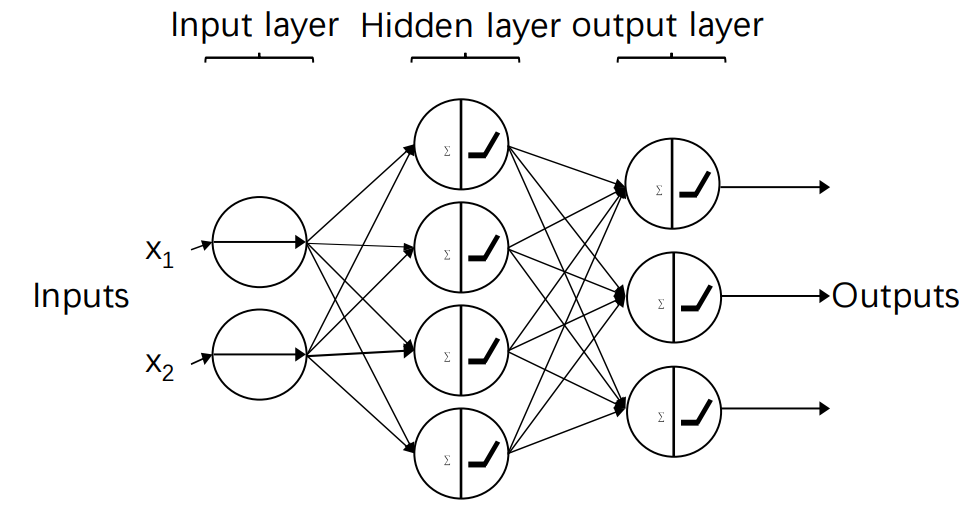
다층 신경망은 입력층과 출력층 사이에 하나 이상의 뉴런 층이 존재하는 신경망이다.
이 층을 은닉 층 (Hidden Layer)이라고 한다.
다음 뉴런 층에 완전히 연결된 형태 (Fully Connected)
출력은 지정값 이상의 경우 1, 그렇지 않을 경우 0을 출력한다.

하지만 모든 레이어의 모든 뉴런에 theta를 넘겨 주어야 하기 때문에 번거러움이 발생한다.

그래서 아래와 같이 bias 뉴런으로 표현함으로써 번거러움을 해결하였다.

유념할 점은 출력 층을 제외한 모든 레이어에 bias 뉴런을 포함했다는 점이다.
3-1. MLP에서는 학습 모드와 테스트 모드가 존재한다.
학습 모드는 입력으로 제시된 데이터들의 특징 혹은 패턴을 학습하는 모드이며,
테스트 모드는 학습 모드의 결과를 이용하여 새로운 데이터에 적용하는 모드이다.
일반적으로 우리가 생활에서 "수업을 통해 학습을 하고 시험을 통해 테스트하여 피드백을 받는다"로 이해하면 되겠다.
수업을 듣는 우리처럼 MLP에서의 학습 모드는 오래 걸리고, 시험은 빠른 시간 내에 끝난다.
3-2. MLP를 학습시키는 방법으로 1986년에 제안된 역전파 (Backpropagation) 학습 알고리즘을 사용한다.
대략적으로 각 학습 인스턴스에 대해 예측을 수행하고 오류를 측정한다. (forward pass)
그 다음 역순으로 각 뉴런 층을 통과하며 각 연결의 오류 기여도를 측정한 후, 연결 가중치를 약간 조정하여 오류를 줄이는 방식이다. (backward pass)
알고리즘
1. 각 뉴런의 연결 가중치 무작위로 초기화
2. 학습 오류가 없거나 종류 조건을 만족할 때까지 아래 과정 반복
a. 학습 데이터 인스턴스 선택 -> 입력층에 제시하고 순방향으로 뉴런의 출력 값 계산 -> 출력 층 뉴런들의 출력값 계산
b. 출력층의 실제 출력과 target값을 이용하여 학습 오차 계산
c. 출력층에서 입력층 방향으로 계산된 오차를 바탕으로 뉴런 연결치의 변화량 계산
d. 모든 뉴련의 연결 가중치 변화량 계산이 끝나면 실제로 각 연결 가중치의 값을 갱신
3-3. MLP에서는 activation 함수로 단계 함수 대신 Logistic 함수와 Sigmoid 함수를 사용한다.
(시그모이드 함수는 로지스틱 함수의 특수한 경우이다.)


그 외에도 tanh나 ReLu 등 다른 activation 함수가 사용될 수 있다.
- activation 함수들의 특징
로지스틱 함수는 0~1 사이 값, tanh 함수는 -1~1 사이 값 출력
학습 과정에서 미분 값이 사용되어 미분 가능의 여부가 중요하다.
ReLu는 그래프와 같이 z=0에서 미분 불가능이지만, 실제로는 잘 작동한다.
Relu는 계산 속도가 빠르고 최대 출력값에 제한이 없다는 장점이 있다.

- activation 함수 선택
이진 분류의 경우 0과 1 사이의 출력 값을 얻기 위해 Logistic 함수를 사용한다.
임계값을 0.5로 설정하여 이 값 이상이면 양의 클래스로, otherwise는 음의 클래스로 분별한다.
다중 분류의 경우 softmax 함수를 사용한다.
softmax 함수는 뉴런 별로 구분하는 것이 아닌, 모든 뉴런 출력을 함께 고려하여 아래와 같이 정규화하는 함수이다.

예를 들어 출력 뉴런 값이 0.1, 0.1, 0.3일 경우, softmax를 적용하면

로 변경된다.
단 회귀 분석 문제의 경우 활성화 함수를 적용하지 않는다.

4. 경사 하강법 (Gradient Descent, GD)
경사 하강법 : 비용 함수를 정의하고, 이 함수의 값을 최소화하기 위해 반복적으로 매개 변수를 조정하는 것
(첫 매개 변수는 랜덤 값)
비용 함수(loss function, 예: MSE)를 줄이기 위해 시도하면서 단계적으로 값을 개선한다. -> 최소 수렴할 때까지 반복한다.

4-1. 학습율
학습율이 너무 낮으면 알고리즘이 최적의 솔루션에 도달하지만 시간이 오래 걸린다.
반대로 너무 높으면 알고리즘이 발산하여 최적의 솔루션을 찾을 수 없다.
해결책으로 학습율을 크게 하여 학습 속도를 빠르게 진행하게 하고, 점차 학습율을 줄여 천천히 변하도록 한다.

경사하강법은 탐색 공간 내에 불규칙한 지형이 있을 경우 최적의 해를 찾기가 어렵다.
따라서 전처리를 통해 스케일을 동일하게 맞추어 주어야 탐색 시간이 줄어든다.
스토케스틱 경사 하강법 (stochastic gradient descent : SGD)
매 학습 단계에서 학습 세트에서 무작위로 한 인스턴스를 선택하고, 그 인스턴스만을 기반으로 Gradient를 계산한다.
알고리즘이 훨씬 빨라지고, 거대한 훈련 세트를 훈련할 수 있는 장점이 있다.
하지만 확률(랜덤) 성질로 인해, 덜 규칙적이고 최적의 해에 수렴하지 않게 될 수 있는 단점이 존재한다.
Backpropagation Algorithm에 대한 수기 계산